
Read summarized version with
What is Speech-to-Text?
Speech-to-text is technology that turns spoken language into written text through artificial intelligence and speech recognition algorithms. You might also hear it called voice-to-text or automatic speech recognition (ASR). The process works by capturing audio through a microphone, analyzing sound wave patterns, and translating them into digital text you can edit, store, and share.
Today’s speech-to-text software relies on machine learning and deep learning models trained on massive amounts of audio data. These systems have gotten remarkably good at recognizing different accents, filtering out background noise, and using context to tell apart similar-sounding words. Some of the more sophisticated solutions can even identify who is speaking and add punctuation on their own.
For professionals who need to create documentation quickly, speech-to-text has become something of a game-changer. It lets you capture information much faster than typing ever could. This is particularly useful for documenting processes where subject matter experts can narrate workflows as they work.
Key Characteristics of Speech-to-Text
- Real-time transcription: Converts speech to text on the fly as you speak, making live captioning and immediate documentation possible
- AI-powered accuracy: Uses machine learning algorithms that get better over time, adapting to specific voices and industry terminology
- Multi-language support: Can recognize and transcribe multiple languages and dialects, sometimes detecting the language automatically
- Speaker identification: More advanced systems distinguish between different speakers and label the transcript accordingly
- Integration capability: Connects with video conferencing tools, content management systems, and documentation platforms, enabling seamless digital modernization workflows
Speech-to-Text Examples
Example 1: Meeting Documentation
Picture a project manager who uses speech-to-text during team meetings to capture discussions, action items, and decisions automatically. Rather than scrambling to take notes by hand, the software records everything that gets said and produces a searchable document. Team members who missed the meeting can catch up without anyone needing to summarize.
Example 2: Training Content Creation
A subject matter expert records themselves explaining a complex procedure while speech-to-text software converts their narration into written documentation. This approach is particularly useful for capturing tacit knowledge quickly, and it creates a solid starting point for learning resources and standard operating procedures.
Speech-to-Text vs Voice Commands
| Aspect | Speech-to-Text | Voice Commands |
|---|---|---|
| Purpose | Converts speech into editable text documents | Triggers specific actions or functions |
| Output | Written transcription | System response or action |
| Use case | Documentation, transcription, note-taking | Device control, software navigation |
How Glitter AI Helps with Speech-to-Text
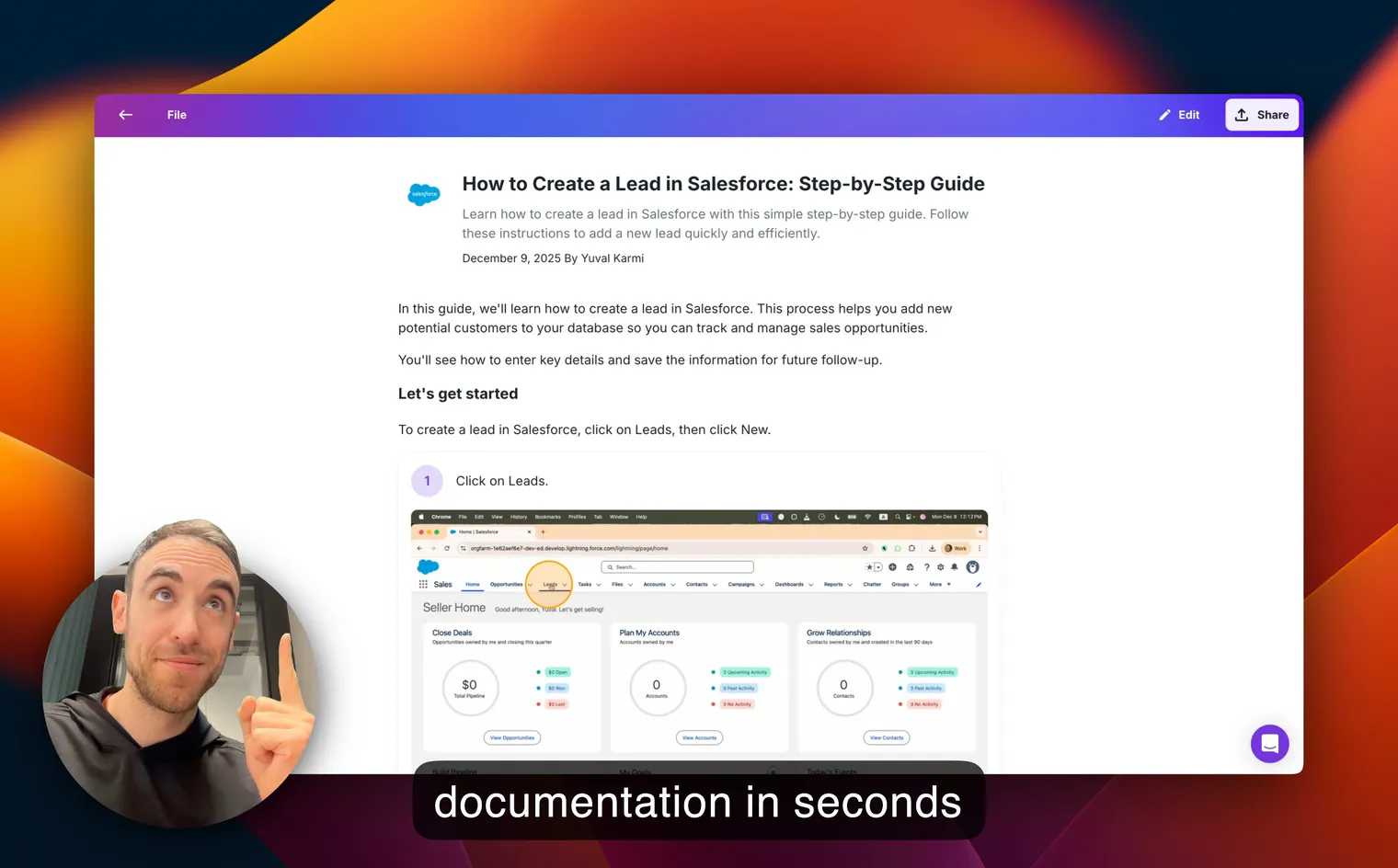
Glitter AI builds speech-to-text technology right into its documentation workflow. When you record your screen or narrate a process, Glitter automatically transcribes the audio into text that becomes part of your documentation. No need to write out explanations manually or use separate transcription tools.
You can edit and format the transcribed text, then combine it with screen recordings to create comprehensive training guides and process documentation, all without the tedium of typing everything out yourself. The same approach extends to existing recordings through video to text conversion, so older training footage becomes searchable documentation too.
Teach your co-workers or customers how to get stuff done – in seconds.

Frequently Asked Questions
What is speech to text technology?
Speech to text technology uses artificial intelligence to convert spoken words into written text. It allows for voice-based documentation, transcription, and dictation without requiring manual typing.
How does speech recognition software work?
Speech recognition software takes in audio, breaks it into small sound segments, matches those segments to words using AI algorithms, and then assembles them into readable text.
What is the difference between speech to text and voice to text?
There is no real difference. Speech to text and voice to text are simply different names for the same technology that converts spoken language into written text.
Can speech to text software understand different accents?
Yes. Modern speech to text software trains on diverse audio samples, so it can recognize various accents, dialects, and speaking patterns with reasonably high accuracy.
Is speech to text accurate for technical terminology?
Most speech to text software learns industry-specific terms over time. Many solutions also let users add custom vocabulary for specialized terminology.
What is the best speech to text software for documentation?
It depends on what you need. Look at accuracy, integration options, language support, and whether it fits into your existing documentation workflow.
Can speech to text be used for creating training materials?
Absolutely. Subject matter experts can narrate procedures, and the software converts their explanations into written documentation that serves as a foundation for training content.
Does speech to text work offline?
Some speech to text solutions work offline with on-device processing, while others need an internet connection for cloud-based AI processing.
How can speech to text improve productivity?
Speaking is typically three to four times faster than typing. Speech to text lets you create content faster, which can significantly cut down documentation time.
Can speech to text identify multiple speakers?
Advanced speech to text software includes speaker diarization, a feature that identifies and labels different speakers in a conversation or recording.