Read summarized version with
First time I shadowed a service desk, I watched one engineer answer the same Okta MFA reset question four times before lunch. Four tickets. Four near-identical Slack threads. Four customers waiting. By the fifth, she had a script taped to her monitor.
That’s the gap a service desk SOP closes. Not with more bureaucracy. Just by making sure the fifth ticket doesn’t feel like the first.
I’m Yuval, CEO of Glitter AI. We help support teams turn the work they’re already doing into documentation customers and coworkers can actually use. What follows is the SOP I wish that engineer had on day one. Every stage of the ticket lifecycle, the SLAs that actually matter, the scripts worth standardizing, and the mistakes I keep hearing about from IT support managers.
Teach your co-workers or customers how to get stuff done – in seconds.

What a service desk SOP actually is
A service desk SOP, sometimes called a help desk SOP, is the written playbook your tier-1 and tier-2 agents follow to handle tickets consistently. It covers intake, triage, troubleshooting, escalation, closure, and the post-incident loop. Done well, a new hire’s third week starts to look a lot like a senior agent’s third year. Same priorities. Same scripts. Same handoffs.
Most teams I talk to have pieces of this written down somewhere. The password-reset runbook is in Confluence. The on-call rotation lives in PagerDuty. The escalation matrix exists in someone’s head. The point of a real SOP is to gather all of it in one place where people can actually find it, with clear ownership at every step.
If you want a more formal definition, see our service desk SOP glossary entry. For the broader context of how this fits with other IT documentation, IT documentation best practices covers the foundation.
The frameworks worth knowing
You don’t need an ITIL certification to run a good service desk. Two pieces of ITIL keep coming up though, because they hold up:
- ITIL Service Operation - the day-to-day model for running support, covering event management, incident management, request fulfillment, problem management, and access management.
- ITIL Incident Management - the specific lifecycle for restoring service after disruption: identify, log, categorize, prioritize, diagnose, escalate, resolve, close.
The SOP below maps cleanly onto both. If your team is on Jira Service Management, ServiceNow, Zendesk, or Freshservice, the workflows are already structured around these stages. Your job is mostly to write down what your team does inside each one.
Stage 1: Ticket intake
Owner: Tier-1 agent on duty (or automated routing) SLA target: First response within 15 minutes for P1, 1 hour for P2, 4 hours for P3, 1 business day for P4
Tickets show up through one of a handful of channels: email, web portal, chat, phone, or a Slack or Teams integration. Your SOP should spell out what happens in the first 60 seconds for each.
Required fields at intake
Every ticket should capture, at minimum:
- Requester name and contact method
- Affected system or service
- Short description (one sentence)
- Long description (what they were trying to do, what happened, what they expected)
- Business impact (one user, a team, a department, the whole company)
- Time the issue started
- Steps already attempted
If your form lets people skip fields, they absolutely will. Make business impact and affected system mandatory. Those two are what drive triage.
Canned response: acknowledgement
Hi [Name],
Thanks for reaching out. I've logged your request as ticket [#####]
and I'm taking a look now. You'll hear back from me within
[SLA window] with either a resolution or next steps.
If anything changes on your end (the issue gets worse, more people
are affected, or it resolves itself), reply to this email and the
ticket will update automatically.
[Agent name]Common mistake: firing the auto-ack and calling intake done. The auto-reply confirms receipt. The agent reply confirms a human is on it. Do both.
Stage 2: Triage and prioritization (P1-P4)
Owner: Tier-1 agent or triage lead SLA target: Priority assigned within 10 minutes of intake
Priority is the single most important field on any ticket. Get it wrong and you either burn an engineer on a non-issue, or you leave a real incident rotting in the queue.
The standard P1-P4 model looks like this:
| Priority | Definition | Example | Response | Resolution target |
|---|---|---|---|---|
| P1 - Critical | Service down, multiple users blocked, revenue at risk | Production app offline, email outage | 15 min | 4 hours |
| P2 - High | Major feature broken, single team blocked, no workaround | VPN failing for one office, payroll system error | 1 hour | 8 hours |
| P3 - Medium | Single user blocked, workaround exists | Account locked out, printer offline | 4 hours | 1 business day |
| P4 - Low | Request, question, cosmetic issue | New equipment request, “how do I” questions | 1 business day | 3 business days |
Calibrate these for your business. A SaaS company’s P1 isn’t a hospital’s P1. Write the definitions down with real examples so a new agent can self-triage on day one.
The two-question triage script
When a ticket comes in fuzzy, agents should ask two questions before assigning a priority:
- “How many people are affected right now?”
- “Is there a way you can keep working while we fix it?”
Those two answers map directly onto priority. One person with a workaround is P3 or P4. A whole team with no workaround is P2. Multiple teams without a workaround is P1.
Common mistake: letting requesters pick their own priority. Everyone thinks their ticket is urgent. The triage agent owns the priority call based on impact and workaround, not on tone.
Stage 3: Categorization and routing
Owner: Tier-1 agent SLA target: Routed within 15 minutes
Categories decide who handles the ticket and feed your reporting later. A clean category tree usually has a top level (Network, Account Access, Hardware, Software, Request) and one sub-level (Software → Microsoft 365 → Outlook).
Resist the urge to grow the tree past two levels. Three-level taxonomies look thorough on a slide deck, but agents never apply them consistently, and your reporting turns into noise.
Routing rules to write down
- Which categories auto-assign to which queues
- Which categories require approval before routing (e.g., software purchases)
- Which categories trigger automatic notifications (e.g., security incidents to the SOC)
- What to do when a ticket spans categories (default to the most-blocking system)
Teach your co-workers or customers how to get stuff done – in seconds.
Stage 4: Troubleshooting workflows by category
This is the part of the SOP that earns its keep. For each major category, write out a step-by-step troubleshooting flow any tier-1 agent can follow. The four below cover roughly 80% of tier-1 volume.
Network issues
- Confirm scope: one user, one location, or company-wide? Check the network status dashboard before doing anything else.
- If company-wide: declare incident, page network on-call, post to status page.
- If one location: check switch and AP status, contact site lead.
- If one user: ping their device, check VPN status, verify they’re on the right SSID, check DHCP lease.
- Walk the user through restart of network adapter, then full reboot.
- If unresolved after 20 minutes, escalate to tier-2 with diagnostics attached.
Account access (password resets, MFA, lockouts)
- Verify identity using two of: employee ID, manager confirmation, video call, security questions. Never reset on email request alone.
- For password reset: trigger self-service flow first; only manual reset if self-service is broken.
- For MFA reset: verify identity, clear MFA enrollment in the IdP (Okta, Entra, Duo), send re-enrollment link.
- For account lockout: check failed-login source (their device, a forgotten session, or suspicious activity).
- Document the verification method used in the ticket.
This category alone is usually 30%+ of tier-1 volume. It’s also the most automatable, and the place where written SOPs pay back fastest.
Hardware issues
- Capture model, serial, location, and warranty status.
- Run the standard diagnostics for the device class (laptop, monitor, peripheral, phone).
- Check for known issues in the asset’s history.
- If under warranty: open vendor case, attach ticket number.
- If out of warranty or vendor confirms hardware failure: check spare inventory, ship replacement, schedule pickup of broken device.
- Update the asset record before closing.
Software issues
- Confirm version installed vs. supported version.
- Check the application’s status page if it’s SaaS.
- Reproduce the issue if possible (or get screen recording from the user).
- Search the knowledge base before troubleshooting from scratch.
- If reproducible and not in KB, work the issue and create a KB article on resolution.
- If not reproducible, request a screen recording with steps and escalate to tier-2 if the user can’t provide one.
For every one of these flows, spell out what gets documented in the ticket: the exact diagnostic commands run, the user-side actions taken, the result of each step. A future agent reading this ticket should be able to pick up the work without asking the user to start from scratch.
Stage 5: SLA tracking
Owner: Service desk lead, with daily review by team SLA target: SLA breach rate under 5% per priority tier
SLAs only work if someone is actually watching them. Most ticketing tools (Jira Service Management, ServiceNow, Zendesk, Freshservice) ship with SLA tracking built in. Turn it on, configure the priority targets above, and set up:
- Real-time SLA breach alerts to the team channel
- A daily morning review of tickets at risk
- Weekly review of breach trends by category and assignee
- Monthly review with leadership on overall performance
Common mistake: treating SLA breaches as individual failures. Most breaches are systemic. Wrong category. Wrong queue. Missing knowledge article. On-call gap. Track patterns, not just incidents.
Stage 6: Escalation paths
Owner: Whoever is currently assigned the ticket SLA target: Escalation triggered within 50% of remaining SLA window
Escalation is where good service desks pull away from average ones. Your SOP has to spell out when to escalate, to whom, and what to hand off.
Tier-1 to tier-2
Trigger when:
- Tier-1 has worked the standard troubleshooting flow without resolution
- The ticket requires elevated permissions
- 50% of the SLA window has passed without resolution
- The user explicitly requests escalation
Handoff should include: ticket history, diagnostics already run, what was ruled out, what hypothesis to test next.
Tier-2 to tier-3 (or vendor)
Trigger when:
- Tier-2 confirms the issue is in vendor-owned code or infrastructure
- The fix requires a code change or configuration the team doesn’t own
- The ticket has been open more than one full SLA cycle
Handoff should include everything from tier-1/2 plus a written reproduction path and any logs collected.
The “stuck” escalation
If a ticket has had no activity for the lesser of 4 hours or 50% of its remaining SLA, it should escalate automatically. Not because the agent failed. The agent is probably heads-down on something else, and the ticket just needs new eyes. Write this rule into your tool’s automation.
Incident management SOPs cover the full lifecycle for major incidents, which runs parallel to standard tier-2/tier-3 escalation. Worth a read if you don’t have one yet.
Stage 7: Knowledge base article creation
Owner: Resolving agent, reviewed by team lead SLA target: KB article drafted within 24 hours of resolution for any first-time issue
Every ticket your team resolves for the first time should produce a knowledge base article. This is the step most teams skip, and most teams later regret skipping.
The criteria for “yes, this needs a KB article”:
- The issue affects multiple users or is likely to recur
- The resolution required steps not already documented
- A user could resolve it themselves with the right instructions
- A new agent would benefit from seeing the resolution path
What goes in a KB article
- Title (matches what users would search: “How to reset MFA in Okta”, not “MFA Reset Procedure v2.1”)
- Symptoms (what the user sees)
- Cause (one or two sentences, plain language)
- Resolution (numbered steps, with screenshots)
- Verification (how to confirm it worked)
- Related articles
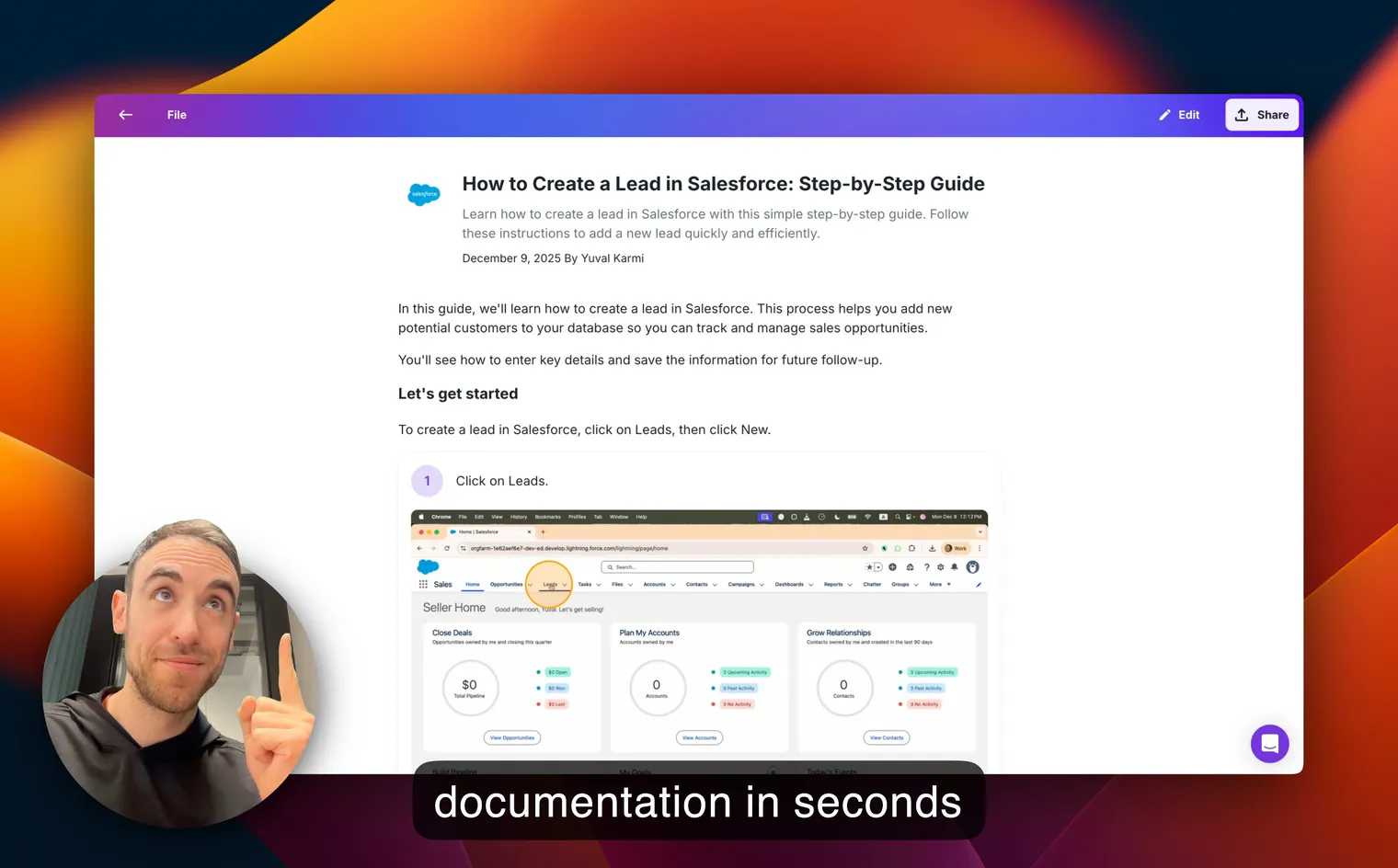
This is exactly where Glitter fits. The usual KB workflow goes: agent resolves ticket, agent writes up steps, agent grabs screenshots, agent stitches it all into Confluence or whatever KB tool you use. That’s 30-60 minutes per article. Which is why agents tend to skip it.
With Glitter, the agent just screen-records the resolution the first time they do it. The recording turns into a step-by-step guide automatically: captioned screenshots, written instructions, blurred sensitive data. The “how do I reset MFA in Okta” recording becomes the article that quietly closes the next 50 identical tickets without an agent ever opening them.
That’s the unlock for tier-1. Every ticket becomes a documentation opportunity, and the documentation costs nothing to produce. See how Glitter works for IT support teams for the workflow.
Record the resolution once. Glitter writes the guide. The next 50 tickets self-serve.
Stage 8: Ticket closure and customer notification
Owner: Resolving agent SLA target: Closure within 1 hour of resolution
Closing a ticket is more than clicking “resolved.” A clean close has four parts:
- Resolution summary in the ticket - what actually fixed it, in plain language. Future-you will thank present-you.
- Notification to the requester - what was done, what to do if it happens again, link to a KB article if there is one.
- Category and resolution code - these feed reporting. Don’t skip them even when it’s tempting.
- Customer satisfaction request - auto-triggered after closure, kept to one or two questions.
Canned response: resolution
Hi [Name],
Your ticket [#####] is now resolved. Here's what we did:
[2-3 sentence summary in plain language]
If this comes up again, you can resolve it yourself using this guide:
[link to KB article]
If you're still seeing the issue, just reply to this email within
the next 7 days and the ticket will reopen automatically. After 7
days, please open a new ticket so we don't lose track.
Thanks for your patience,
[Agent name]Common mistake: auto-closing with no summary. Six months later, when the same user runs into the same problem, the only context the next agent inherits is the word “resolved.” Write the summary every time.
Stage 9: Post-incident review for repeat issues
Owner: Service desk lead, monthly cadence SLA target: Review completed within 5 business days of month close
The point of the SOP isn’t just to handle today’s tickets. It’s to make tomorrow’s tickets either easier or unnecessary. Once a month, the lead should pull:
- Top 10 ticket categories by volume
- Top 5 tickets that breached SLA
- Any ticket that was reopened more than once
- Any ticket that escalated to tier-3
For each, ask:
- Why did this happen?
- Why did it take this long to resolve?
- What would prevent the next one?
The fix is usually one of: better KB article, better automation, training gap, missing monitoring, or an underlying problem ticket that needs an owner. Track these as action items with owners and due dates, and review the previous month’s actions at the same meeting.
For broader IT operations context, essential IT SOPs covers the procedures that should sit alongside your service desk SOP: change management, access reviews, backup verification, and the rest.
Stage 10: On-call rotation handoff
Owner: Outgoing on-call, confirmed by incoming on-call SLA target: Handoff completed at the scheduled rotation time, no exceptions
On-call gaps are where P1 tickets go to die. Your SOP needs a handoff procedure that takes 10 minutes and doesn’t lean on anyone’s memory.
Handoff checklist
- Status of any open P1 or P2 tickets, with current owner and next step
- Any planned maintenance or change windows during the next on-call shift
- Any known issues or workarounds that are still in effect
- Any tickets the outgoing on-call escalated to tier-3 that need follow-up
- Pager and tooling access confirmed by the incoming on-call (don’t assume, actually log into the tool)
- A handoff message posted in the team channel so everyone else knows who’s on
The handoff should happen live (video or voice) for the first 90 days a new person is in the rotation. Written-only is fine once trust is there.
Tools that fit the SOP
The SOP itself is tool-agnostic, but most teams end up implementing it in one of these:
- Jira Service Management - strong if your team already lives in the Atlassian ecosystem, deep automation, native Confluence integration for the KB
- ServiceNow - the enterprise default, the strongest workflow engine, and the heaviest configuration overhead
- Zendesk - easiest to roll out, best for customer-facing support, lighter on ITSM features
- Freshservice - solid mid-market pick, ITIL-aligned out of the box, good price-to-features ratio
Pick the one your team will actually use. The best tool is the one your agents don’t actively avoid.
Templates to start with
If you’d rather not start from a blank page, here’s the starter set every service desk SOP should include:
- Intake form template (required fields above)
- Triage decision matrix (P1-P4 table above)
- Category and routing tree (top level + one sub-level)
- Troubleshooting flows for the four main categories
- Escalation matrix (tier-1 → tier-2 → tier-3 with criteria and contact methods)
- KB article template (title, symptoms, cause, resolution, verification)
- Canned responses (acknowledgement, resolution, escalation notification, satisfaction survey)
- On-call handoff checklist
- Monthly review template
Drop these into a shared Confluence space, a Notion page, or whatever KB tool you use. Link to them from your ticketing tool so agents find them in the flow of work, not buried three folders deep.
The mistakes I see most often
After enough conversations with IT support managers, the same mistakes keep coming up:
- Writing the SOP once and never updating it. Tools change. Vendors change. Your business changes. Put a quarterly review on the calendar.
- Treating the SOP as a compliance document. If agents only see it during onboarding and audits, it’s not a SOP, it’s a binder. Link to it from the ticket workflow itself.
- Over-categorizing. Three-level taxonomies kill reporting. Two levels max.
- Skipping the KB article. Every skipped article is a future ticket you’ve signed up to handle from scratch.
- Letting requesters set priority. Everyone’s ticket is urgent to them. Triage agents own priority.
- No closure summary. “Resolved” is not a resolution.
- Vague escalation criteria. “When you’re stuck” isn’t a criterion. Write the actual trigger.
- No post-incident loop. If the same ticket comes in 50 times and nothing changes upstream, you’re running a hamster wheel, not a service desk.
Frequently Asked Questions
What is a service desk SOP?
A service desk SOP is the written playbook your tier-1 and tier-2 agents follow to handle support tickets consistently. It covers ticket intake, triage, prioritization, troubleshooting, escalation, knowledge base creation, closure, and post-incident review.
What are the P1-P4 priority levels in a service desk?
P1 is critical (service down, multiple users blocked), P2 is high (major feature broken, no workaround), P3 is medium (single user blocked with workaround), and P4 is low (requests, questions, cosmetic issues). Each priority tier maps to a specific response and resolution SLA.
How do I write a help desk SOP?
Start by mapping the ticket lifecycle from intake to closure, then document each stage with owner, SLA target, required fields, scripts, and common mistakes. Use a framework like ITIL Service Operation as your scaffold and validate each procedure with the agents who will actually run it.
What is the difference between a service desk SOP and an IT support SOP?
A service desk SOP focuses specifically on the ticket lifecycle - intake, triage, routing, escalation, and closure. An IT support SOP is broader and includes other procedures like change management, access reviews, asset management, and backup verification. The service desk SOP usually sits inside the larger IT support SOP library.
How are SLAs typically structured in a service desk SOP?
SLAs are structured by priority and by stage. Common targets are: P1 first response in 15 minutes and resolution in 4 hours, P2 in 1 hour and 8 hours, P3 in 4 hours and 1 business day, P4 in 1 business day and 3 business days. Each stage of the lifecycle (triage, routing, escalation, closure) also has its own SLA.
Which ITIL processes apply to a service desk SOP?
ITIL Service Operation provides the overall model, with ITIL Incident Management defining the specific lifecycle for restoring service after disruption. Request Fulfillment, Access Management, and Problem Management are also commonly referenced for service desk procedures.
What tools work best for implementing service desk procedures?
Jira Service Management, ServiceNow, Zendesk, and Freshservice are the most common platforms. Each supports SLA tracking, automated routing, and knowledge base integration. The best fit depends on your team size, ITIL maturity, and existing tooling ecosystem.
How should tickets escalate from tier-1 to tier-2?
Escalate when tier-1 has completed the standard troubleshooting flow without resolution, when the issue requires elevated permissions, when 50% of the SLA window has passed, or when the user explicitly requests escalation. The handoff should include ticket history, diagnostics run, and the next hypothesis to test.
How do you reduce repeat tickets on a service desk?
Capture every first-time resolution as a knowledge base article so the next user can self-serve. Run a monthly post-incident review on top ticket categories and SLA breaches to identify systemic fixes. Recording the resolution as a screen capture turns a one-off fix into a reusable guide that closes future identical tickets.
What should be in a knowledge base article for IT support?
A KB article should include a search-friendly title, the symptoms users see, a plain-language cause, numbered resolution steps with screenshots, a verification step, and links to related articles. Titles should match what users actually search, not internal naming conventions.
The bigger point
A service desk SOP isn’t a static document. It’s the operating system for your support team. The thing that turns individual heroics into a repeatable, measurable, improvable process. Teams that get this right aren’t the ones with the longest SOP. They’re the ones who treat it as a living document, link to it from the tools agents use every day, and feed it with what they learn from every resolved ticket.
If your team is still answering that Okta MFA question for the fifth time this morning, the SOP isn’t really the problem. The problem is that the resolution from the first four tickets isn’t sitting somewhere the next user can find it. Close that loop and the rest of the SOP starts working a lot harder for you. - Yuval, CEO of Glitter AI