Read summarized version with
The first time I had to offboard someone fast, I forgot Okta.
Not the laptop. Not the email. Not the Salesforce seat. Okta. The person kept active SSO into half our stack for two days because the offboarding “process” lived in the head of an IT contractor who happened to be on vacation. Nothing got breached, but the audit log was embarrassing.
If you run IT at a small or mid-sized company - IT Manager, IT Director, IT Support lead, or an MSP juggling ten clients - this story sounds familiar. The work is mostly screenshot-heavy clicking through admin consoles: Active Directory, Okta, JumpCloud, Workday Admin, Salesforce Admin, Intune, the VPN portal. And the docs? Usually missing, stale, or buried in someone’s Notion that nobody else opens.
I’m Yuval, founder of Glitter AI. A big chunk of our users are IT folks documenting exactly this kind of work. This post is the list I wish I’d had when I started: the 12 IT SOPs every IT team should have written down, with scope, owner, key steps, audit trail, and the gaps I keep watching teams fall into.
For the broader playbook on how to structure all of this, I’ve also got a longer piece on IT documentation best practices. A separate SOP template guide pairs well with this post too.
Teach your co-workers or customers how to get stuff done – in seconds.

Why IT SOPs Are Different From Other SOPs
Most SOPs describe a workflow. IT SOPs describe a workflow plus a control.
When AP skips a procedure, you get a late payment. When IT skips one, you get a compliance finding. Or an open SSO session for an ex-employee. Or a server that quietly stopped getting patched six months ago. Auditors care. Regulators care. Your cyber insurance carrier definitely cares.
That’s why every IT SOP in this list ties back to a real framework - ITIL for service management, NIST 800-53 for security controls, or SOC 2 for trust services criteria. You don’t need to memorize the frameworks. But your SOPs should give an auditor enough evidence to check the box without scheduling a meeting with you.
Quick definitions if you want them: I keep simple working definitions on the IT SOP glossary page. There are also deeper dives for incident management SOPs and the change management procedures that sit alongside them.
Now the list.
1. New User Account Provisioning
Scope: Everything needed to turn “we hired Sarah” into “Sarah can do her job on day one.”
Owner: IT Support Specialist or Systems Admin. For MSPs, this usually sits with the L1/L2 helpdesk lead.
Key steps:
- Receive ticket from HR or HRIS (Workday, BambooHR, Rippling) with role, manager, start date, and department.
- Create the identity in your IdP (Okta, JumpCloud, Entra ID / Azure AD, Google Workspace).
- Assign group memberships based on role. Group-based access is the only thing that scales - never assign apps individually.
- Provision laptop from inventory, enroll in MDM (Intune, Jamf, Kandji), apply baseline policy.
- Send welcome email with first-login instructions and MFA enrollment link.
- Log the provisioning ticket and tag the assets in your asset tracker.
Audit trail: Ticket ID, IdP audit log entry, MDM enrollment record, asset tag.
Common gaps: Provisioning that bypasses groups (“just give her the same access as Mike”). That one shortcut is how access creep starts, and how SOC 2 access reviews turn into a nightmare three quarters later.
2. Offboarding and Account Deactivation
Scope: Every system the person could log into yesterday should be closed today.
Owner: IT Support Specialist, with the manager and HR signing off.
Key steps:
- Trigger from HR (offboarding ticket or HRIS termination event). For involuntary terminations, this happens before the conversation with the employee.
- Disable the user in the IdP - this should cascade SSO sessions across every connected app.
- Revoke any non-SSO accounts. Every IT team has a handful: legacy admin consoles, vendor portals, shared accounts. Make a list once and keep it.
- Wipe and retrieve the laptop via MDM. Keep the device quarantined until you’ve confirmed wipe.
- Forward email, transfer file ownership, hand over slack DMs and active tickets to the manager.
- Close the offboarding ticket with a checklist of every system touched.
Audit trail: IdP deactivation timestamp, MDM wipe confirmation, ticket with checklist, signed manager handover.
Common gaps: The one I lived through. Offboarding that only kills the laptop and forgets SSO sessions can stay alive in browsers for hours after the IdP user is “disabled.” Force session revocation. Don’t just disable the account.
3. Password Reset and Self-Service Recovery
Scope: How users reset their own password and how IT handles the cases self-service can’t.
Owner: IT Support Specialist (helpdesk).
Key steps:
- User attempts self-service reset via the IdP password reset flow.
- If self-service fails, user opens a ticket via the helpdesk portal - never DM, never email, never Slack.
- Helpdesk verifies identity. Two factors: a callback to the user’s known phone number plus a video call confirming the face matches the HR record. Email-only verification is how social engineering wins.
- Trigger a password reset link or temporary password through the IdP.
- Force MFA re-enrollment if the reset was triggered by suspected compromise.
- Log the reset reason and verification method in the ticket.
Audit trail: Ticket ID, IdP password change event, MFA re-enrollment log if applicable.
Common gaps: Helpdesk staff resetting passwords based on Slack DMs or a familiar voice on the phone. This is the #1 vector for help-desk-driven account takeovers in 2026. Make the verification step non-skippable in the SOP.
Teach your co-workers or customers how to get stuff done – in seconds.
4. Software Install and License Management
Scope: Approving, installing, tracking, and reclaiming software licenses.
Owner: Systems Admin or IT Manager. License budgets often roll up to the IT Director.
Key steps:
- User requests software via the helpdesk portal with a business justification.
- IT checks the software request against an approved-software list. Anything off-list goes to security review.
- Approved? Push the install via MDM (Munki, Intune, Kandji) or assign a license in the SaaS admin console.
- Tag the license in your SaaS management tool (Torii, Zylo, Productiv) or a spreadsheet if you’re earlier stage.
- Reclaim licenses on offboarding and during quarterly inactive-user reviews.
Audit trail: Approval ticket, install/license assignment record, license inventory entry.
Common gaps: Shadow IT. Someone expenses Notion and suddenly your sensitive docs sit in an unmanaged tenant. The SOP needs an explicit “IT must own the tenant” rule, plus a quarterly expense audit for SaaS purchases.
5. Patch Management and Updates
Scope: Keeping operating systems, browsers, and core business apps up to date across the fleet.
Owner: Systems Engineer or Cloud Engineer. For MSPs, this is a managed service deliverable.
Key steps:
- Pull the patch advisory feed for each platform (macOS, Windows, Linux distros, Chrome, key SaaS).
- Classify patches by severity (critical, high, medium) and SLA (24h, 7d, 30d).
- Stage patches in a test ring (IT team’s own machines first), then pilot ring (volunteers), then full rollout.
- Deploy via MDM with maintenance windows and reboot policies that respect working hours.
- Track compliance - what % of fleet is patched within SLA - in a dashboard, not a vibes-based check.
- Document exceptions (machines that can’t patch, with a remediation plan and expiration date).
Audit trail: Patch deployment logs from MDM, compliance % by reporting period, exception register.
Common gaps: No staging ring. Pushing a patch fleet-wide, then discovering at 9am Monday that it killed the VPN client - that’s a career event. Always have a test ring and a rollback step.
6. Backup and Disaster Recovery
Scope: How critical data gets backed up, where it lives, and how you restore when things break.
Owner: Systems Engineer or Cloud Engineer, with CTO sign-off on the disaster recovery (DR) plan.
Key steps:
- Identify the data that matters: production databases, file storage, source control, key SaaS exports (Salesforce, HRIS, finance system).
- Define RPO (recovery point objective) and RTO (recovery time objective) for each data class. Document the numbers.
- Configure automated backups with encryption at rest and an immutable retention policy.
- Store at least one copy off-platform (the “3-2-1 rule”: 3 copies, 2 media types, 1 offsite).
- Test restores quarterly. A backup you’ve never restored from is not a backup. It’s a hope.
- Run a tabletop DR exercise annually with the engineering and ops leads.
Audit trail: Backup job logs, encryption key rotation records, quarterly restore test reports, DR tabletop notes.
Common gaps: Untested backups. Every IT person knows this, and most teams still skip the quarterly restore because nothing’s gone wrong yet. The SOP should make the restore test a non-negotiable calendar event with a named owner.
7. Incident Response (P1, P2, P3)
Scope: How IT triages, communicates about, and resolves incidents - from “Slack is down” to “we have a confirmed compromise.”
Owner: IT Director or on-call rotation lead.
Key steps:
- Define severity tiers. Roughly: P1 is company-wide outage or active security incident, P2 is a major function broken for a team, P3 is degraded but workable.
- Page the on-call. P1 wakes people up. P2 triggers within business hours. P3 enters the queue.
- Open an incident channel (Slack #incident-NNN) and assign three roles: Incident Commander, Comms Lead, Subject Matter Expert.
- Communicate updates on a fixed cadence: P1 every 15 min, P2 every hour. Even if the update is “still investigating.”
- Resolve. Close the incident. Mark the timeline.
- Post-incident review (PIR or “blameless postmortem”) within 5 business days for any P1 or P2.
Audit trail: Incident ticket, Slack incident channel transcript, status page updates, PIR document.
Common gaps: No fixed comms cadence. Stakeholders panic when they don’t hear anything, then they start DMing the engineers, who stop fixing the incident to answer DMs. Locking in a “we update every 15 minutes no matter what” rule is probably the single biggest improvement you can make.
8. Change Management (RFC and CAB)
Scope: How any production change - code deploy, infra change, firewall rule, IdP policy update - gets reviewed and approved.
Owner: IT Director or Change Manager. Larger orgs have a Change Advisory Board (CAB) that meets weekly.
Key steps:
- Submit a Request for Change (RFC) ticket with: what’s changing, why, blast radius, rollback plan, scheduled window.
- Classify the change: standard (pre-approved, low risk, documented), normal (needs CAB review), emergency (post-hoc review allowed).
- Normal changes go to the CAB for sign-off. Standard changes follow the documented playbook. Emergency changes get a special expedited approver (usually the IT Director or CTO).
- Execute during the approved maintenance window with the rollback plan ready.
- Verify post-change. If any production signal breaks, roll back first, debug second.
- Close the change ticket with outcome and any follow-up actions.
Audit trail: RFC ticket, CAB meeting notes, approval timestamps, post-change verification record.
Common gaps: Treating every change as “emergency” to skip review. If 80% of your changes are emergencies, you don’t have an emergency process. You have no process. Tighten the standard-change catalog so the easy stuff flows without the CAB, and the rest actually gets reviewed.
9. MFA Enrollment and Recovery
Scope: Getting every user enrolled in MFA, and recovering them when they lose their second factor.
Owner: IT Support Specialist (enrollment) and Security Lead (policy).
Key steps:
- New users complete MFA enrollment as part of provisioning. Block app access until enrollment is complete.
- Prefer phishing-resistant factors: hardware keys (YubiKey), passkeys, or platform authenticators. SMS is a fallback, not a primary.
- Document the recovery process for lost devices: in-person verification, video verification with HR record, or hardware key handoff from a fresh inventory.
- Re-enroll affected users after any reset and audit recent recoveries weekly to spot social engineering attempts.
- Quarterly: report MFA coverage to leadership. Anything less than 100% on critical apps is a finding.
Audit trail: IdP MFA enrollment log, recovery tickets, quarterly coverage report.
Common gaps: SMS-only MFA on admin accounts. SIM swaps are real, and your domain admin is the worst possible account to lose. Hardware keys for IT staff aren’t optional.
10. VPN and Remote Access Setup
Scope: How remote employees and contractors get secure access to internal resources.
Owner: Systems Engineer or Network Engineer.
Key steps:
- Determine access need based on role. Most modern stacks should default to zero-trust (per-app access via Cloudflare, Tailscale, Zscaler, Twingate) instead of broad VPN tunnels.
- Provision client config via MDM. Users should not be manually copying tokens or certs.
- Enforce device posture: managed device + up-to-date OS + active EDR. Unmanaged personal devices don’t get tunnel access.
- MFA on every connection.
- Log all sessions and review weekly for anomalies (unusual geo, off-hours access, repeated failures).
- Auto-revoke contractor access on the contract end date. Don’t trust manual cleanup.
Audit trail: Connection logs, device posture reports, contractor access expiration calendar.
Common gaps: Standing VPN access for everyone “just in case.” This breaks the principle of least privilege and turns one phished laptop into network-wide exposure. Move toward per-app, time-bound access.
Teach your co-workers or customers how to get stuff done – in seconds.
11. Asset Tracking and Hardware Lifecycle
Scope: Every device the company owns, from the day it’s purchased to the day it’s destroyed.
Owner: IT Support Specialist or Operations Coordinator.
Key steps:
- Procurement: Asset is purchased, tagged with a unique asset ID, and entered into the asset tracker (Snipe-IT, ServiceNow, a clean spreadsheet).
- Deployment: Asset is enrolled in MDM, assigned to a user, and the assignment is logged.
- Maintenance: Repairs, upgrades, and warranty events are recorded against the asset ID.
- Reassignment: If the asset moves between users, wipe and re-enroll, then update the assignment record.
- Retirement: Wipe with documented method (NIST 800-88 sanitization), record the certificate of destruction or the buyback receipt, mark the asset as retired in the tracker.
Audit trail: Asset tracker history, wipe certificates, disposal records.
Common gaps: Dead inventory. Laptops that left the office during an offboarding three years ago and never came back. Run a physical audit once a year and reconcile against the tracker. Whatever’s missing, assume it contains data, and go find it.
12. Phishing and Security Incident Reporting
Scope: How any employee reports a suspected phishing email, social engineering attempt, or security event - and how IT responds.
Owner: Security Lead, with helpdesk handling first-line triage.
Key steps:
- Make reporting frictionless. A “Report Phishing” button in Gmail or Outlook that sends to a monitored inbox or PagerDuty queue.
- Auto-acknowledge the report so the user knows it landed.
- Helpdesk triages: is this a known campaign, a new campaign, or a confirmed compromise?
- If confirmed compromise: pivot to the Incident Response SOP (#7). Don’t try to handle it as a one-off.
- If campaign-only: pull the email from other inboxes, block sender, update email security rules, post a brief in #it-announcements so the rest of the org knows to watch for it.
- Close the loop with the reporter - even a one-line “thanks, you spotted a real one” trains the org to keep reporting.
Audit trail: Report inbox or queue history, response time SLA, monthly phishing-report stats.
Common gaps: No feedback loop. Users report once, hear nothing back, and stop reporting. Phishing reporting is as much a culture problem as a tools problem, and IT owns the culture here.
How to Actually Document IT SOPs Without Losing a Week
Here’s the thing about IT SOPs. Every one of them is mostly clicking through an admin console. AD, Okta, JumpCloud, Workday Admin, Salesforce Admin, Intune, the VPN portal. Screenshots upon screenshots upon screenshots.
If you sit down to type one of these out manually - open the screen, grab a screenshot, paste it, write the caption, repeat 40 times - you’ll burn a full afternoon on a single SOP. Multiply by 12 procedures and that’s most of a week gone. Which is why most IT teams never finish their runbook library.
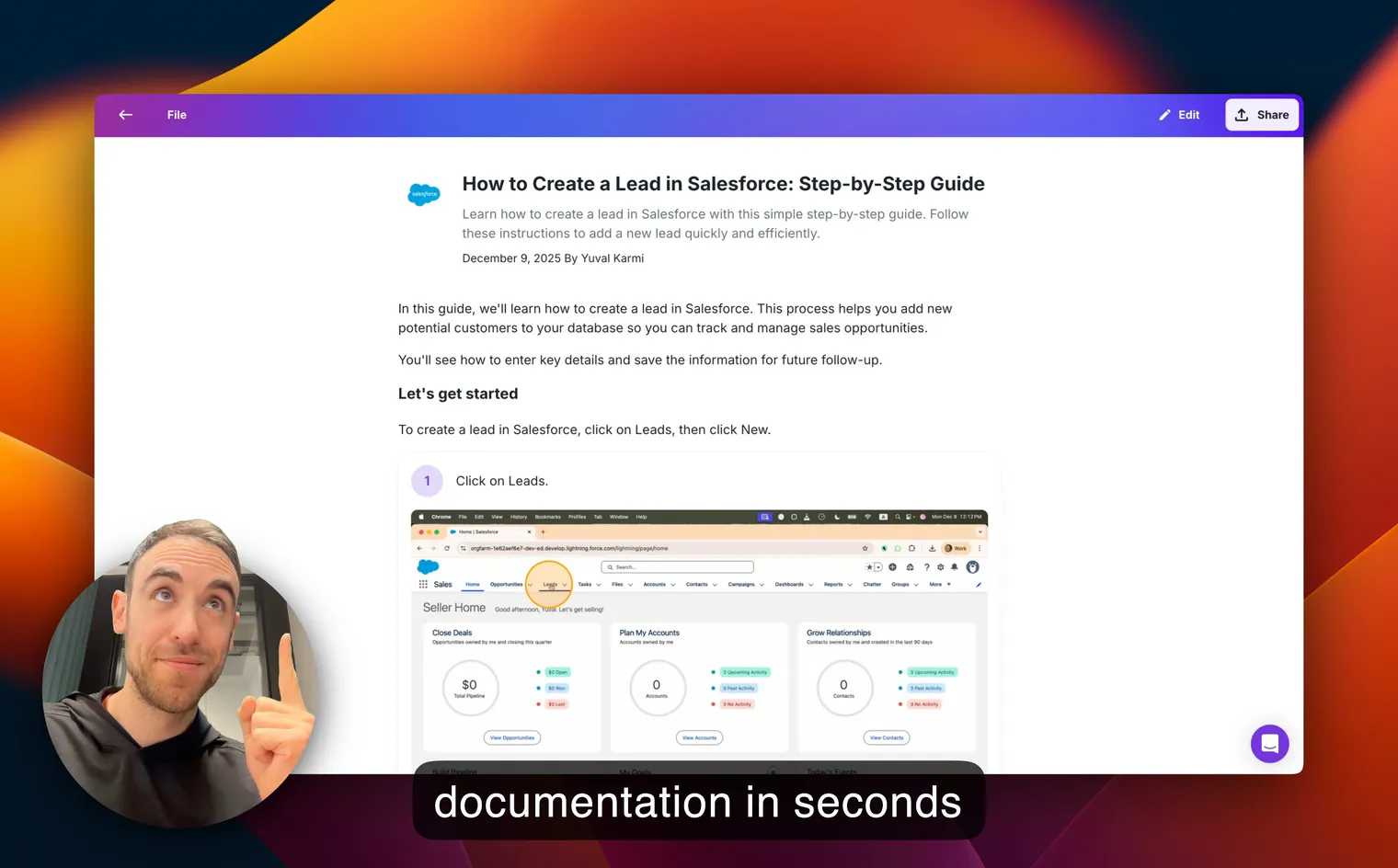
The way I’d do it now: just record the screen once while you’re doing the task for real, and let an AI turn the recording into a step-by-step doc with screenshots already pulled, captions already written, and sensitive fields already blurred. That’s literally what I built Glitter AI’s SOP generator for, and it’s the use case our IT Support solution was designed around.
Whatever tool you use, the principle is the same. Stop typing IT runbooks. Record them. Your job is the work, not narrating the work.
Glitter AI turns your screen recording into a step-by-step SOP with screenshots, captions, and blurred sensitive data.
Mapping IT SOPs to Frameworks (ITIL, NIST, SOC 2)
If you have an audit on the calendar, here’s the rough mapping. Not exhaustive, but enough to orient you.
- Provisioning and offboarding (#1, #2) → SOC 2 CC6.2 (logical access), NIST AC-2 (account management).
- Password reset and MFA (#3, #9) → SOC 2 CC6.1, NIST IA-2 (identification and authentication).
- Software and patch management (#4, #5) → SOC 2 CC7.1, NIST SI-2 (flaw remediation), CM-7 (least functionality).
- Backup and DR (#6) → SOC 2 A1.2 (availability), NIST CP-9 (backup), CP-10 (recovery).
- Incident response (#7, #12) → SOC 2 CC7.3 / CC7.4, NIST IR-4 (incident handling), ITIL Incident Management.
- Change management (#8) → SOC 2 CC8.1, NIST CM-3 (change control), ITIL Change Enablement.
- Remote access (#10) → SOC 2 CC6.6, NIST AC-17 (remote access).
- Asset management (#11) → SOC 2 CC6.1, NIST CM-8 (information system component inventory).
Every SOP in your library should reference the controls it supports. When an auditor asks “show me your evidence for CC6.2,” you should be able to point to a specific SOP, a specific run log, and call it a day.
Final Take
IT SOPs aren’t the fun part of the job. They’re the part that keeps you out of trouble. With auditors, with your CFO, with your future self when the on-call phone rings at 2am.
The 12 procedures above are the ones I’d document first if I were starting from scratch tomorrow. Pick the three that scare you the most - probably offboarding, incident response, and backup restores - get those written this month, and work through the rest one per week.
And please, please record the screen instead of typing it all out. Your time is better spent on actual work than narrating a click in Okta for the 400th time. - Yuval / Founder & CEO, Glitter AI
Frequently Asked Questions
What is an IT SOP?
An IT SOP (standard operating procedure) is a documented, repeatable process that an IT team follows for a specific task - like provisioning a new user, responding to an incident, or applying a patch. Good IT SOPs include scope, owner, key steps, and an audit trail so the work is consistent and reviewable.
What are the most important IT SOPs to document first?
If you're starting from scratch, document new user provisioning, offboarding, incident response, change management, and backup/restore procedures first. These five cover the highest-risk and most-audited workflows in any IT environment.
How many IT SOPs should an IT team have?
Most small and mid-sized IT teams need somewhere between 12 and 30 documented SOPs covering identity, endpoint, network, security, and service management. The 12 essential procedures in this post are the core; the rest are extensions specific to your stack.
What is the difference between an IT SOP and an IT runbook?
An IT SOP describes how a recurring process should be performed end-to-end, including ownership and approval steps. An IT runbook is usually narrower - a click-by-click set of instructions for executing a specific operational task. Most IT SOPs contain one or more runbooks inside them.
How do IT SOPs map to SOC 2 and NIST 800-53?
Each IT SOP should reference the controls it supports. For example, provisioning maps to SOC 2 CC6.2 and NIST AC-2, change management maps to SOC 2 CC8.1 and NIST CM-3, and backups map to SOC 2 A1.2 and NIST CP-9. The SOP plus its run logs become your audit evidence.
Who owns IT SOPs in a small company?
In smaller companies, the IT Manager or IT Director typically owns the SOP library, with individual procedures owned by the role that performs them - Systems Admin, IT Support Specialist, Security Lead, or Cloud Engineer. For MSPs, ownership sits with the service delivery manager for each client.
How often should IT SOPs be reviewed and updated?
Review every IT SOP at least annually, and any time the underlying tool, vendor, or framework requirement changes. High-risk SOPs like incident response and offboarding should be reviewed quarterly and tested at least once a year through tabletop exercises or simulated runs.
What is the fastest way to document IT runbooks?
Record the screen while you perform the task, then let an AI tool turn the recording into a step-by-step document with screenshots and captions. This is roughly 11x faster than typing the SOP from memory, and it captures the actual current-state workflow rather than an idealized version.
What should be in an IT incident response SOP?
An IT incident response SOP should define severity tiers (P1, P2, P3), paging rules, the three core incident roles (Commander, Comms Lead, SME), a fixed status update cadence, and a post-incident review process. Every P1 and P2 should produce a written timeline and a blameless postmortem within five business days.
What are common gaps in IT SOPs?
The most common gaps are missing approval thresholds, unverified password resets, untested backups, no fixed incident comms cadence, treating every change as 'emergency' to skip review, and SMS-only MFA on admin accounts. Each of these is a documented audit finding waiting to happen.